چانکینگ(تکهسازی) در رگ سیستمها
مدلهای هوش مصنوعی مولد قابلیتهای بسیاری دارند که امکان انجام کارهای زیادی را فراهم میکند. اما در کنار این قابلیتها، محدودیتهایی نیز دارند. از جمله مشکل توهم(Hallucination) و عدم دسترسی به دادههای شخصی. برای حل این مشکل RAG سیستمها به وجود آمدهاند که ما آن را در متیس با نام پایگاه دانش میشناسیم. برای آشنایی با RAG سیستمها میتوانید این مقاله از متیس را مطالعه کنید. زمانی که قصد دارید یک منبع داده مانند یک کتاب و یا یک وبسایت را به پایگاه دانش بدهید تقریبا اولین عملیاتی که بر روی آن انجام میشود عملیات چانکینگ یا تکهسازی است. این مرحله شاید مهمترین بخش یک پایگاه دانش باشد. در ادامه قصد داریم به معرفی این مفهوم و الگوریتمها و فرایندهای آن در متیس بپردازیم.
چانکینگ چیست؟
قبل از این که به سراغ پاسخ دادن به این سوال برویم نیاز است تا بدانیم منبع دادهای که در پایگاه دانش قرار گرفته چگونه استفاده میشود. بعد از بارگذاری منبع داده، سیستم آن را تکه تکه میکند. سپس تکهها در یک پایگاه دادهی مخصوص ذخیره میشوند و فایل منبع دادهای که بارگذاری کردهاید حذف میشود. این بخش اول از کار یک پایگاه دانش است، بعد از این بخش پایگاه دانش ایجاد شده. اما چگونه از پایگاه دانش استفاده میشود؟
هر زمان که کاربر سوالی را از ربات شما میپرسد ربات به سراغ پایگاه دانش میرود و تکههایی را که از لحاظ معنایی با سوال کاربر ارتباط بسیار نزدیکی دارند از پایگاه دانش دریافت میکند. بعد از این مدل زبانی سعی میکند با داشتن سوال کاربر و دانش مربتط(تکههایی که از پایگاه دانش دریافت کرده) به سوال کاربر پاسخ دهد. این دو مرحله یک پایگاه دانش را تشکیل میدهند.
اما چرا منبع داده در بخش اول تکه تکه یا اصطلاحا چانک میشود؟ منبع دادهای که بارگذاری میکنید طولانی هستند. این منابع معمولا شامل چندین دانش نامرتبط نیز هستند. مثلا یک کتاب را در نظر بگیرید که به عنوان منبع دانش به یک پایگاه دانش داده میشود. این کتاب اولا طولانی است و دوما هر فصل یا حتی هر صفحه(یا حتی چند) از آن نیز دربرگیرندهی موضوع خاصی باشد. اما مورد دوم چه اشکالی ایجاد میکند؟ وقتی سوالی از سمت کاربر مطرح میشود هم پیدا کردن بخش مرتبط با سوال کاربر بسیار سخت است هم این که اگر پیدا شود مقدار زیادی اطلاعات نامرتبط با آن نیز وجود دارد که به سمت مدل ارسال میشود. پس چانکینگ از چندین بعد دارای اهمیت است. اما به سراغ پاسخ دادن به سوال اصلی برویم. چانکینگ چیست؟
به طور خلاصه در مرحلهی چانکینگ، منبع دادهای که بارگذاری کردهاید به قطعات کوچکتری شکسته/خورد میشود.
روشهای چانکینگ در RAG System
حقیقت امر این است که با وجود اهمیت بسیار بالای این مبحث هنوز روش کاملی که برای تمام موارد پاسخگو باشد وجود ندارد. اما روشهای چانکینگ را میتوان به طور کلی به دو دسته تقسیم کرد: ۱- تکه کردن بر اساس متن(چانکینگ ساختاری). ۲- تکه کردن بر اساس محتوا(چانکینگ معنایی). همان طور که از اسامی پیداست شما میتوانید یک متن را بر اساس ساختار یا معنای آن تقسیمبندی کنید. مثلا تمام متن یک کتاب را به تکههای ۱۰۰ کاراکتری تقسیم کنید. یا بر اساس علائم نگارشی مانند نقطه یا ویرگول تقسیمبندی را انجام دهید. در تقسیمبندی معنایی تکهها بر اساس معنا از یکدیگر جدا میشوند. در واقع در این روش سعی میشود هر تکه شامل یک معنا باشند، نه این که بخشهای هممعنا یک تکه تشکیل دهند. اما به سراغ چانکینگ ساختاری برویم و توضیح آن چه در متیس روی میدهد.
چانکینگ بر اساس طول متن در متیس
الگوریتمهایی که در متیس به کار گرفته میشوند بر اساس ساختار متن کار میکند. دو الگوریتم Unstructured و FAQ در متیس وجود دارند که به توضیح آنها در متیس میپردازیم. هر دو الگوریتم پارامترهای مشخصی دارند:
حداقل حروف: حداقل طول هر تکه باید چند حرف باشد. این مقدار به صورت پیشفرض بر روی ۱۰۰ تنظیم شده و این یعنی تلاش میشود هیچ تکهای کمتر از ۱۰۰ حرف نباشد.
حداکثر حروف: این پارامتر مشخص میکند اندازه چانکها حداکثر باید چند حرف باشد. این مقدار نیز به صورت پیشفرض بر روی ۶۰۰ تنظیم شده است و این یعنی تلاش میشود هیچ تکهای بیش از ۶۰۰ حرف نباشد.
حداکثر حروف در همپوشانی دو تکهی متوالی: با تنظیم مقدار این پارامتر میتوانید مشخص کنید که دو چانک متوالی آیا میتوانند همپوشانی داشته باشند یا خیر؟ مقدار این پارامتر به صورت پیشفرض بر روی صفر تنظیم شده که یعنی چانکها هیچ همپوشانیای نداشته باشند. اگر مقداری به غیر از صفر تنظیم کنید یعنی اجازهی همپوشانی تکهها را به آن مقدار دادهاید.
مدلهای امبدینگ تدارک دیده شده نیز از بهترین مدلهای حال حاضر هستند که زبان فارسی را پشتیبانی میکند. ممکن است مدلهای امبدینگ دیگری باشند که برای مواردی بهتر عمل کنند اما این مدلها در مجموع برای زبانها و کاربردهای مختلف از بهترینها هستند.
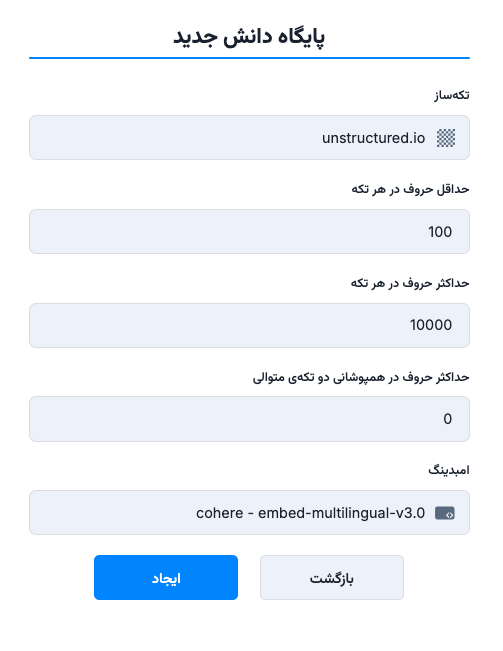
چانکر Unstructured به نوعی یک چانکر عمومی است و برای بسیاری از موارد کاربرد دارد. تنها در صورتی که نوع پایگاه دانش شما FAQ باشد بهتر است از چانکر FAQ استفاده کنید. این چانکر برای فایلهای ورد که به صورت سوال-جواب هستند و بین هر سوال و جواب چند خط فاصله است و یا فایلهای اکسلی که یک ستون سوال و یک ستون جواب دارند بهتر عمل میکند.